Denis前天写了很标题的文章“如何学淘宝封百度”,我看后颇有看法。在我接触的blogger里,很少看到有比较喜欢百度的,就我个人而言,我不喜欢它。不,是对它反感。即使它给可能吧带来流量了,老实地说,它带来的流量没有Google带来的那么有价值,下面说说我对百度的看法,这只是我眼中的百度。你可以认为,这是一个有Google依赖症的人所写的体会,不客观。但我可以告诉你,博客就是不客观的。

十大罪状
1、不尊重原创
这点对于原创博客来说是致命伤,如果你相信可能吧上的文章是原创的,你可以尝试在Google和百度搜索同一篇文章的标题,比如搜索“外连 网络硬盘”(Google,百度),你会看到,在Google里,可能吧的链接排在第一位,而在百度里,排第一位的是百度空间的。从文字你看有看出,排第一位的结果是转载我的文章(2008年9月8日12:36分数据)
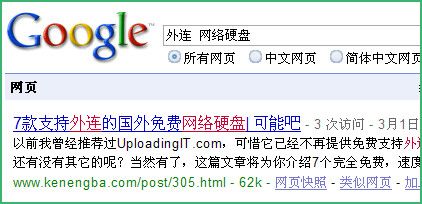
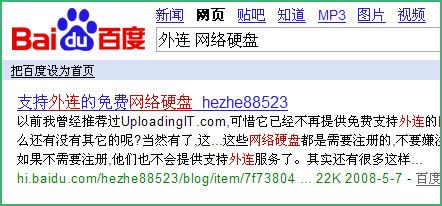
2、扼杀原创
紧接着第一点。
可能百度认为,只要提供搜索者匹配的内容就足够了,那么这是个抄袭的页面。可能他认为,这对于搜索者来说,看起来没有什么不一样。
但这种想法是大错特错的!互联网本无内容,原创网站多了,内容也就多了。如果原创网站一直无法有较好的排名,于是放弃创作,内容从哪里来?
所幸的是,Google并没有像百度这样狭隘的想法。
3、误导点击竞价排名广告
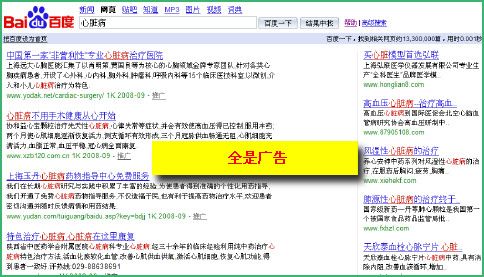
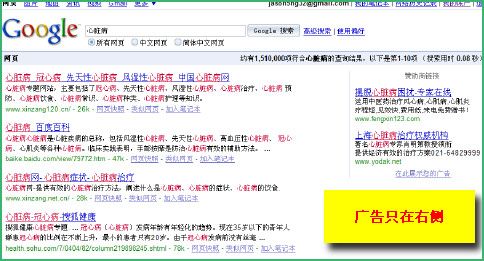
这样就结果是很明显的:很多人会误点百度竞价排名的广告,而只有需要的人才会点击Google搜索结果上的广告。
这对于搜索者来说,会造成极大的骚扰。
4、对广告主造成伤害
紧接着第三点。
我认为,百度将竞价排名结果与普通结果混合排列的做法不但对于搜索者来说是一种恶心的行为,更深入一点,对于广告主来说未必是好事,误点进去的人可能并没有购买广告里的产品的欲望,而是被误导进去的,但百度却是收了广告主的广告费。
也许,这就是百度的高明之处、赚钱之道,这是否可以反映出百度的一种想法:中国网民的平均素质偏低,很容易误点广告,我们就从中赚钱吧!
5、利己结果
在百度的搜索结果里,你经常会看到百度贴吧、百度知道、百度百科的结果的排名比较靠前。这不是偶然,因为百度将自己的产品的权重调的比较高,以致于只要关键词相对比较匹配,自身产品的结果就会比较靠前。
事实上,百度知道、贴吧、空间、百科里有很多内容都是没有标明原文链接的活生生的抄袭!
这再一次显示了百度不尊重原创的决心。
6、搜索结果不公正性
紧接着第5点。
由于百度搜索结果里出现利己结果,这样的结果就显然失去了公正性。
在搜索引擎地位越来越重要的今天,搜索引擎作为互联网的入口之一,保持其公正性是十分重要的。
Google在这方面做得是非常好的,有时你会看到百度知道、贴吧的结果在Google里比较靠前,而不是Google自己的Blogger博客,这就是一种公正性的体现。
7、流氓软件-百度搜霸
我不知道有多少人受过百度搜霸的困扰,至少前天我的一个朋友就是因为百度搜霸无法卸载而重装电脑。
百度搜霸,从“霸”字也许可以反映出其霸道的一面-安装后无法正常卸载,卸载后还有残余。
其它浏览器的Toolbar都称之为“工具栏”,百度却称之为“搜霸”,搜索公正性都做不好,只能霸占用户浏览器的默认搜索引擎来“霸”吗?
8、没有原因地拔毛或K站
不管你上哪个站长论坛,你都会经常看到有人说被百度拔毛或K站。
拔毛是指大量删除某网站的索引,而K站则是只留下该站首页或0结果。
可能吧去年4月被K了一次,今年被K了2次。
百度在其官方文档里有K站的原因说明,但从绝大多数站长论坛里看到,这只是百度的障眼法,事实上只要你的网站百度不喜欢,随时人工K你。
9、不继续做竞价排名就不被收录
很多站长都在说这样一个事实:之前在百度做了竞价排名,但后来不做,于是就被百度K了。
在这个过程中百度会打至少一次电话给站长,问是否继续做竞价排名,如果你的回答是否,如果百度因此生气了,后果将会很严重-K你没商量。
因此有些站长戏说,“看到百度来电话我就害怕了”。
10、哗众取宠的行为
这是我个人对很反感的行为。在四川地震赈灾期间,百度做了一个捐款排行,只在“百度”后面加上“截止目前已捐”,其它企业都是名称+捐款数额。

下面是一些传闻,无法考证:
11、不尊重robots.txt
robots.txt是搜索引擎行业里公认的网站对搜索引擎爬虫作出索引指示的文件,存放在网站根目录。也就是说,这个文件描述了哪些页面允许爬取,哪些不允许。
但百度虽然口里说尊重robots.txt,但实际上可能还会派匿名爬虫去爬不允许百度收录的网站。
淘宝前几天在robots.txt里限制了百度爬虫,不让百度收录其任何页面,我相信百度不会敢动淘宝,不然就会是大笑话了。
12、百度会派匿名爬虫疯狂爬取网站
去年CPH经历得最多的就是百度爬虫的匿名爬取了,它导致CPH瘫痪了很多次。这种情况尤其在17大期间,为什么?原因可能是第13点。
13、百度会向政府举报(可能)违法网站
当发现某网站有违规的信息,百度会向政府反映,可能是博取好感,或其它什么的。我不知道,这只是传闻而已。
总结
你可以看到,这篇文章多么不客观啊,别相信我,自己去试试。一般而言,搜索一些娱乐性的信息,百度和Google的结果没有多大的差别,但一旦搜索技术性的内容,差别就显示出来了。很多所谓的电脑高手,其实就是搜索高手,而接触得越多你会发现,他们基本上不会用百度,也不会使用“为什么电脑上不了网”这样的关键词进行搜索。
百度的确可恶!为国产悲哀!
老大,看到pr=5了,
但你不要走,你走会哭死一大片的!
我还在,放心。
🙂
嗯嗯,百度是条狗!!
很严重的罪名!!
百度的蜘蛛非常之流氓。
从来都是疯狂的爬,很多服务器都会被爬瘫痪。
而google的蜘蛛到服务器上爬的时候几乎没感觉,但收录结果仍然齐全和快速。
我不知道这是怎样的一个差异。
总结一句:
百度的理念非常之流氓。
也许这是百度的月经定理,平时不来, 一来就让你大出血。
经典
哎,这就是你的不对了.谁较你指望百度纯洁?
女优有女优的把妹方法,你硬要觉得他们看起来很清纯我也没辙吧.
不过百度的确还不错,因为女优有正常的一面,有些人为了生计不得不对一些关键词比较淫荡.
百度我猜测他们的管理很大程度上李彦宏无法做主,而百度似乎没有职业经理人吧.大部分都是技术人员管理一下..
没查资料,妄说而已
但是李彦宏经常自己不能拍板.
两个搜索使用的算法很明显就不同,所以造成了搜索的结果不同。两者的文化不同。
处的政治环境也不同。虽然很多人很赞同你的观点,但是我在这里第一个不赞同,写得有点偏激。大概是因为你网站被k的原因。
在我所知道的,被k肯定是有原因的,也许直接的原因不在你。
了解了
写的很好。。百度的某些做法,的确令人厌恶。
但,,怎么说呢,他的空间是免费的。
百度搜索我不喜欢-___-
我最讨厌的是,百度贴吧和百度知道,几乎没有原创内容,几乎都不标注信息来源
其实看看别人的桌面就知道一个人的电脑水平如何了。百度根本就是挥剑自宫的太监,正一死奴才。
转载内容,已注明出处~~
已经对百度无所谓,Google带的流量是它的10倍多,还恶心的给个绿色认证!迟早把百度拔毛~
绿色认证?什么来的?
作为一个网络用户,无论搜索技术性文章还是娱乐性的文章,google,百度只不过是用户的工具而已,对于只在乎搜索目的的人而言,哪种工具评价好不好并不重要,就如同一把菜刀,哪个牌子不重要,重要的是能不能拿来切菜。我经常会在好几个搜索引擎上同时搜索我想要的结果,有时会在google里有,有时也会在百度里有,当然其他的引擎也有。
说白了这一切不都是钱闹的么?包括你我他!
可惜现在有很多入门级菜鸟青年抱着爱国主义的烂旗支持使用百度。他们怎么就不戒可乐呢。
拿爱国来支持所谓的民族企业是一个可笑的借口。
就我个人而言,我只选对的,不会看它是来自什么地区。
呵呵 可能吧也就靠贬百度来搞流量了
祝福 嘿嘿