robots.txt是存放与网站根目录下的对搜索引擎爬虫列明抓取限制的文件。
淘宝近日在robots.txt里将百度爬虫完全禁止了,也就是说,不允许百度爬虫抓取taobao.com上任何页面。显然,淘宝这一举动是针对百度将要上线的C2C平台而做出的。
但根据新浪科技的采访报道,百度电子商务事业部总经理李明远表示百度正在酝酿绕过淘宝官方,为淘宝用户开辟“绿色通道”,由用户直接提交URL让百度收录。

(pic via)
如果百度真的开辟了这个绿色通道,这将是对其行为操守的一个巨大的讽刺。
为什么这样说呢?
首先从robots.txt说起。
robots.txt能做什么?
1、限制某个搜索引擎不让其爬取
2、限制搜索引擎不让其抓取某些页面
3、其它限制
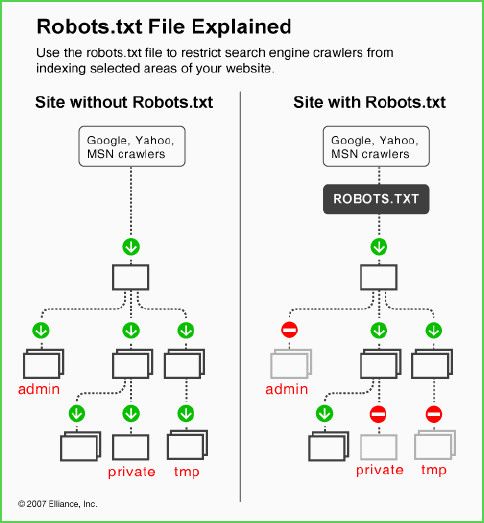
(pic via)
而淘宝的robots.txt里的内容如下:
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
大小写都用了,很明显是要限制百度爬虫,除非百度爬虫不叫baiduspider。
淘宝有权禁止搜索引擎抓取吗?
robots.txt是可以分级的
也就是说,二级域名根目录下也可以放置robots.txt。但是,顶级域名下的robots.txt的权限高于二级、三级域名下的robots.txt。
淘宝店铺URL使用的都是二级域名,不管这些店铺是否愿意被收录,只要taobao.com的robots.txt作出了限制,一切都是NO。
robots.txt规则
搜索引擎会先访问网站根目录的robots.txt文件
在百度的帮助文档里可以看到这一句:
搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。
搜索引擎在爬取一个网站时,会先检查robots.txt,检查有哪些限制,再作出下一步决定。
说到点子上,不管搜索引擎发现某个网站有多少个URL,但只要这个网站的robots.txt里标明不允许搜索引擎抓取,搜索引擎是不能收录这个URL的。
对百度行为操守的质疑
百度遵守robots.txt吗?
这是这篇文章的要讨论的重点。
百度官方帮助文档里有这一句话:
百度严格遵循搜索引擎Robots协议
虽然在百度的十大罪状里说到,有传闻说百度是不遵守robots.txt的,但那毕竟是传闻,我们不妨先相信百度的官方说明。
低劣的行为操守
但是,一旦百度开通了“绿色通道”,允许卖家直接提交URL让百度抓取,这显然是违反了Robots.txt里的规定,而百度又是说自己是“严格遵循”Robots协议的,这可否说是拿石头砸自己的脚呢?
robots.txt不是法律,是准则
虽然robots.txt不是法律,但一旦搜索引擎加入了这个准则,就说明其遵守里面的协议。虽然违反协议内容不会受到法律的制裁,但这样的行为操守显然会受到鄙视。
百度口口声声说自己是遵循Robots规则的,但偏偏要酝酿这个绿色通道,是否可以认为,百度说遵守robots.txt只是个幌子,它事实上是没有规则可言呢?
当然,我希望百度不会真的酝酿这个绿色通道,不然就会成为天下的大笑话了。但既然这句话出自百度电子商务事业部总经理李明远之口,也未必不是事实。

最后说一点题外话,淘宝这种做法是否伤害到商家利益?
搜索一件商品的最好渠道不是通过搜索引擎。因为在搜索引擎里我们看不到价格、款式等商品属性的比较。而购物网站内建的搜索引擎却可以做到这一点。
另一方面,百度搜索结果经常充斥着诱惑点击的竞价排名广告,如果淘宝店铺结果混合在里面,这未必是一件好事。
Denis也写了类似的文章:百度真的遵守 Robots.txt 协议吗?
哈哈!
百度出了个“百付宝” ^_^
不看新闻我还以为是阿里巴巴的分支机构呢,还好不叫护舒宝。
搞不懂,为什么百度出C2C淘宝就要封百度?对淘宝有什么好处吗?百度不收淘宝应该是对自己的C2C有好处啊,为什么要开绿色通道呢?
愚猜测百度是想靠这个举动来亲近淘宝的卖家,让他们觉得淘宝此举是侵害众卖家的利益,而百度的“反击”则是为了维护他们的利益,从而取悦数量众多的卖家,而这些卖家当中说不准会有若干个百分点的人倒戈投入百付宝怀抱,百度就已这部分有C2C经验的卖家为基地,逐步开始分羹淘宝…
百度的竞价搜索把付费链接混合在搜索结果里的做法让很多搜索者误点链接.
如果淘宝的店铺所有人有欺诈行为且使用竞价搜索服务.
如果交易中出现了问题,用户首先质疑的是淘宝而不是百度.
这可能也是淘宝考虑的因素之一,但不是最大的因素。
百度的一些行为,老实说,我觉得很无耻。
百度现在依然收录着淘宝。。
如果网站设置不允许抓取,搜索引擎清除结果可能需要数月的时间,所以,不能以这一点来质疑它的“行为操守”。
哦,这样啊,看来这和主动提交取消索引要求不太一样。我们有个内部论坛,向 google 要求取消索引,过几天就生效了,完全搜索不到了。淘宝没有采取这种最直接的方式,感觉这次表态的成分更大吧。
一般来说出了问题用户会骂淘宝,而不会意识到是百度提供的虚假的信息
因为百度的竞价排名,支持淘宝的行为,不管是出于什么目的,至少对消费者有利的
不过话说回来,一般淘宝的老买家,很少在搜索引擎搜淘宝上的东西吧
至少对于我来说,网上购物,除了买书,我只会到指定的购物网上搜索。
当经济利益正面要求时,坚持原则是很困难的
只不过这次太直白说出来了
这样的说法就让大家觉得比较无耻了。
百度一直以来就没有什么行为操守,从来不用百度,因为你得到的总是他们认为调整的结果,根本没有公正性可言。
这就叫百度的创新意识
还有搜狐博客blog.sohu.com/robots.txt。。。
几小时前刚好有和朋友讨论这个事
顺便COPY过来这里和JASON分享下:
说实话,这次”封索”事件超出了我个人的理解范围,一点没有看懂实质,所有的推测都是基于想象而已.但有几点想象和思践的认识不谋而同:
1)淘宝这一举措应该是出于”必须的”而且是经过全盘斟酌战略部署.很难想象如果是百度先出手而淘宝再防御会是什么景象,当然百度是绝对会有出手的,先发制人是马云的风格也是他擅长的.关于”小卖家利益受损”一说,我的观点是:那不足为道.因为来路渠道方面还有GOOGLE和YAHOO嘛,那TAOBAO和YAHOO什么关系?YAHOO现在和GOOGLE向来关系也不错,现在更是.那GOOGLE和BAIDU又是什么样的关系呢?我想至少他们互相不会喜欢对方吧.所以,少了百度来源对小卖家几乎没啥干系.再用排它法来推算,C2C这一块能与淘宝为敌的也只有百度,所以是”必须的”.
2)内部商业模式方面,”作为淘宝,利用买卖家信息整合资源作为特定增值服务”是符合未来逻辑的,所以从战略意义上,他们的确需要捍卫这块资源不被蚕食,尤其被凶悍的竞争对手掠夺是他们不能容忍的.淘宝是个大卖场也好是个大菜场也好,平台开放相当于变通式的招商引店行为,有人愿意进来开个形象店或有人愿意进来承包做员工餐,甚至引入第三方来管理经营停车厂,目的还是为了更好维护经营环境,提高服务质量.突然来了一家调研公司每天派”蜘蛛”去每个角落调查收集情况,然后宣布他们也要开个大卖场了,你怎么做?很简单,保护和封锁是必须的,然后加强内部管理,提升竞争力.
我能理解和想象的就那么多,两家旗舰式的超级公司之间的战役就目前而言,观察与欣赏的价值远多过判断结果,毕竟战役才刚开始,好戏绝对在后头.
凯瑟琳-泽塔-琼斯 🙂
我同意你的观点,以及汗一个“凯瑟琳-泽塔-琼斯”。
也许有一天所有网站都开始屏蔽不断做恶的百度,看看到时是什么景象。
百度真是越来越讨人嫌了。
百度靠得住,母猪也会上树了!
这篇文章写得好啊
在易趣时代,淘宝也干过这事,整个中国互联网的潜规则都是这样,甚至说中国的C2C都干过这事,淘宝拍拍易趣,那个没有干过。还有一些blog搬家等等,如果我是做市场的,我也会这样干,企业市场经营之道有的时候是不能评论的,换作你,你也可能会这样干,至少在中国的国情下。