robots.txt是存放与网站根目录下的对搜索引擎爬虫列明抓取限制的文件。
淘宝近日在robots.txt里将百度爬虫完全禁止了,也就是说,不允许百度爬虫抓取taobao.com上任何页面。显然,淘宝这一举动是针对百度将要上线的C2C平台而做出的。
但根据新浪科技的采访报道,百度电子商务事业部总经理李明远表示百度正在酝酿绕过淘宝官方,为淘宝用户开辟“绿色通道”,由用户直接提交URL让百度收录。

(pic via)
如果百度真的开辟了这个绿色通道,这将是对其行为操守的一个巨大的讽刺。
为什么这样说呢?
首先从robots.txt说起。
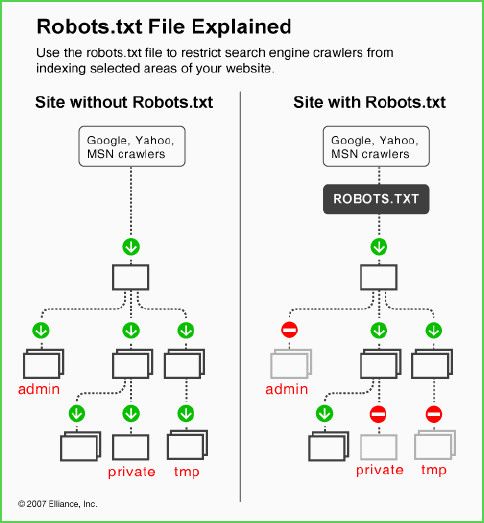
robots.txt能做什么?
1、限制某个搜索引擎不让其爬取
2、限制搜索引擎不让其抓取某些页面
3、其它限制
(pic via)
而淘宝的robots.txt里的内容如下:
User-agent: Baiduspider
Disallow: /
User-agent: baiduspider
Disallow: /
大小写都用了,很明显是要限制百度爬虫,除非百度爬虫不叫baiduspider。
淘宝有权禁止搜索引擎抓取吗?
robots.txt是可以分级的
也就是说,二级域名根目录下也可以放置robots.txt。但是,顶级域名下的robots.txt的权限高于二级、三级域名下的robots.txt。
淘宝店铺URL使用的都是二级域名,不管这些店铺是否愿意被收录,只要taobao.com的robots.txt作出了限制,一切都是NO。
robots.txt规则
搜索引擎会先访问网站根目录的robots.txt文件
在百度的帮助文档里可以看到这一句:
搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件。
搜索引擎在爬取一个网站时,会先检查robots.txt,检查有哪些限制,再作出下一步决定。
说到点子上,不管搜索引擎发现某个网站有多少个URL,但只要这个网站的robots.txt里标明不允许搜索引擎抓取,搜索引擎是不能收录这个URL的。
对百度行为操守的质疑
百度遵守robots.txt吗?
这是这篇文章的要讨论的重点。
百度官方帮助文档里有这一句话:
百度严格遵循搜索引擎Robots协议
虽然在百度的十大罪状里说到,有传闻说百度是不遵守robots.txt的,但那毕竟是传闻,我们不妨先相信百度的官方说明。
低劣的行为操守
但是,一旦百度开通了“绿色通道”,允许卖家直接提交URL让百度抓取,这显然是违反了Robots.txt里的规定,而百度又是说自己是“严格遵循”Robots协议的,这可否说是拿石头砸自己的脚呢?
robots.txt不是法律,是准则
虽然robots.txt不是法律,但一旦搜索引擎加入了这个准则,就说明其遵守里面的协议。虽然违反协议内容不会受到法律的制裁,但这样的行为操守显然会受到鄙视。
百度口口声声说自己是遵循Robots规则的,但偏偏要酝酿这个绿色通道,是否可以认为,百度说遵守robots.txt只是个幌子,它事实上是没有规则可言呢?
当然,我希望百度不会真的酝酿这个绿色通道,不然就会成为天下的大笑话了。但既然这句话出自百度电子商务事业部总经理李明远之口,也未必不是事实。

最后说一点题外话,淘宝这种做法是否伤害到商家利益?
搜索一件商品的最好渠道不是通过搜索引擎。因为在搜索引擎里我们看不到价格、款式等商品属性的比较。而购物网站内建的搜索引擎却可以做到这一点。
另一方面,百度搜索结果经常充斥着诱惑点击的竞价排名广告,如果淘宝店铺结果混合在里面,这未必是一件好事。
Denis也写了类似的文章:百度真的遵守 Robots.txt 协议吗?
从来没有用过百度,不予置评,问题是,就算淘宝不给百度收录,还可以用Google或者Yahoo吧,对小卖家来说该不是太大的问题才对吧
感觉两边都挺无耻的.
现在还没有传出百度抓取了淘宝店的信息的消息。现在还不好说。
百度在我看来完全是个流氓公司…
挂了几天阿里妈妈广告,就K我的博客
博主说这个,未免偏颇了点。
首先,robots限制是有这么回事,但也只是限制搜索引擎爬取而已,对于用户自行提交注册的url,有哪方面来讲也没有约束力。诚然,淘宝的限制对网站用户的影响不大,还有google等可以用,但用户当然也有权利自行注册到百度去,淘宝有资格管吗?对于用户自行注册过来的url,百度有义务根据淘宝的robots去屏蔽吗?甚至说,百度有权力去屏蔽吗?
针对百度来说,因为淘宝的robots限制所以不对其抓取,不就是遵守了robots规则吗?
顺便一说,博主注册个caosibaidu.cn,下作了吧?
我从来不用百度,就用google,百度整个一骗人公司!!
百度真恶心啊,搞了个什么有啊,还只用二级域名,郁闷哦,还百付宝
不知kenengba对youku屏蔽谷歌与百度视频搜索,而谷歌视频还有大量youku内容什么看法,是不是谷歌操守有问题啊 ??
你写这篇文章之前,有没有做过专业的调查?
凡事不能只看表面,看到了某些没有做调查而妄下结论的作者,真的为你感到悲哀!
需要搞清楚一点,淘宝坚决屏蔽百度,一点也不坚决!
分明是淘宝又在讨好百度嘛,看看淘宝的robots.txt写法就知道了.
http://mall.taobao.com/robots.txt
众所周知,根目录下的robots.txt是屏蔽百度以及某个蜘蛛的关键文件。
而淘宝商城的http://mall.taobao.com/ 根目录下,根本就没有robots.txt文件,也就是说,淘宝商城根本就没有屏蔽百度,也没有对任何机器人做限制。
这就很明确的说明,淘宝网心口不一,嘴巴上称坚决屏蔽百度,实际上暗度陈仓,迷惑网友,今天偷偷的撤掉http://mall.taobao.com/跟目录下的robots.txt文件,等百度蜘蛛抓取到了数据后,又悄悄的把robots.txt放上去,朋友们应该知道,只要该网站没有作弊,百度的快照结果会很友好的为你保留很长时间,这是百度的特色功能。
那么淘宝今天可以“偷偷的”把http://mall.taobao.com/根目录下robots.txt去掉,明天就有可能把http://www.taobao.com根目录下的robots.txt去掉,等到百度成功抓取了数据之后又“偷偷的”把robots.txt放上去。这一切的一切,都是悄悄的在人们的眼皮底下进行。
说到这里,那些盲目责怪百度,说百度不要脸,被淘宝屏蔽了还抓取淘宝的人该知道,百度其实很无辜,淘宝才不要脸。
发现这位网友很有先见之明。。www.taobao.com的robots.txt果然被删了。。
百度够阴险的
看了懂了很多呀,谢谢LZ分享这么好的文章
既然robot只是一个准则,百度过几天也可以大方的说robot不适合中国.
我不用淘宝 我准备换Google为首页
您的文章是如此有趣和翔实。我得到了很多有用的和重要的信息。谢谢你这么多。
您的文章是如此有趣和翔实。我得到了很多有用的和重要的信息。谢谢你这么多。
您好!該網站是偉大的。謝謝你為一個偉大的資源