最近“Google图书搜索”成了热门的话题,在过去的10多天里,“谷歌图书”、“Google图书”等词的搜索频率大大提高。原因是中国一些作家、作协和CCTV联合起来,认为Google擅自将有著作权的图书扫描上网侵犯了作家们的权利。和李彦宏出现在春晚之前CCTV对百度发起猛烈攻势一样,这次CCTV再次联合新华网等官媒对Google进行谴责。一些不明真相的记者也随之附和。
Google图书搜索本来并不引人注意,这回CCTV又给Google带来流量了。

Google图书搜索概况
Google图书搜索是Google一个非常有特色的服务,Google通过与图书馆、出版社、作家合作,将图书扫描存档,然后在网上提供搜索和预览。
前面这句话说得这么啰嗦是因为“扫描”、“上网”、“预览”是3个不同的概念。在没有得到出版社或作者许可,Google不会大面积提供图书的预览,甚至不会提供预览,即便它已经将一本图书扫描存档。
Google图书搜索的数据来源:
(1)图书馆
Google和一些知名的图书馆合作,将其收藏的图书索引在图书搜索中。
对于受版权保护的图书,Google图书搜索里会提供片段预览或不提供预览,比如王小峰这本书、张抗抗这本书。而对于不受版权保护的图书,搜索者可以阅读和下载整本图书。
(2)出版商
同时,Google还与一些出版商和作者达成协议,他们的图书也会出现在Google图书搜索上。和图书馆计划中受版权保护的图书一样,这些图书会提供很小的片段预览,以帮助搜索者决定是否购买该书。
Google图书搜索提供预览的方式:
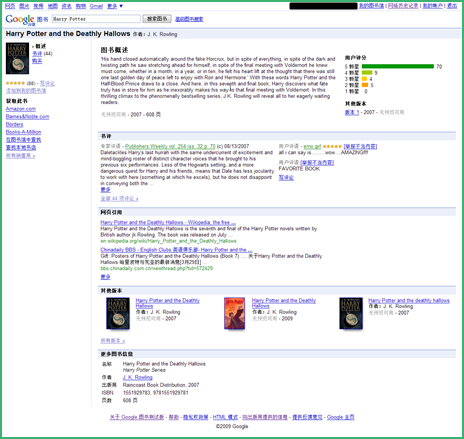
1、无预览
在出版者或作者明确要求不允许提供任何预览的情况下,Google图书搜索只提供图书的书评、作者、ISBN等周边信息。如《Harry Potter》。
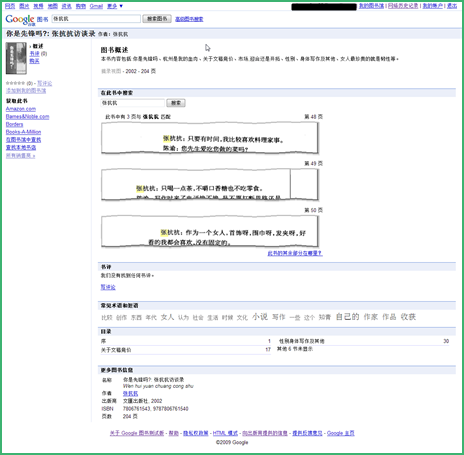
2、摘录预览
对于有版权的图书,Google提供图书的片段预览,这些预览由两三行字组成,而且是不可复制的图片。例如抗议声很大的张抗抗老师的这本书。
3、有限预览
在得到出版社或作者许可的情况下,Google会提供一本书的有限预览,有限预览比摘录预览提供更多公开的内容,比如徐静蕾这本书,至少一半的页面是可以预览的。但这些预览材料是pdf文件,无法复制。

4、全书预览
如果一本书没有版权、版权已经失效、出版社或作者允许公开,Google会提供这本书的全书预览,比如《论语》。
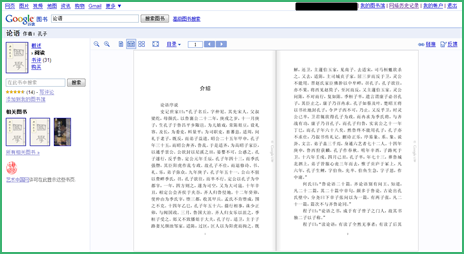
和抄袭内容满天飞的中国互联网不一样,Google提供的每种预览方式都会包括书籍的出版社、作者等权利信息。
世界图书馆
Google之所以要扫描图书无非有2个目的:
增强自身的数据,让其搜索立于不败之地
商业公司当然要首先考虑自己的利益,图书里包含的信息比互联网上的更专业可靠。
让图书检索变得更简单,构建世界图书馆
写过论文的朋友肯定知道翻查资料的痛苦,如果所有的图书都能在网上检索,事情会变得轻松很多。即便不能下载,知道某条信息位于某本书的哪一页也极大地方便了后续查找。

大学图书馆一般都有书目检索系统,里面可能会包含维普数据库、万方数据库等,但这些数据库是远远不够的,同时因为技术原因,搜索结果并不理想,甚至搜索缓慢。
因此,构建一个世界性的、资料大而全的数字图书馆是有必要的,这不但可以让知识永久保存下来(试想纸质图书什么时候会湮灭掉,但电子数据几乎不会丢失),更重要的是,人们可以更方便地查找资料。如果人们愿意,可以以一定的价格购买检索出来的纸质图书或电子文档。
而要构建这样一个数字图书馆,要么由联合国来筹划,要么就是由利益驱动的商业公司来构建。明白到这一点,就不难理解为什么Google要推出图书搜索。
纠纷
前面说到,Google图书搜索里的内容的其中一个来源是合作图书馆。前些年,数位作家和出版社联合起诉Google,他们认为Google在没有获得他们授权的情况下擅自制作电子版图书是侵权的。
Google之所以这么做,因为Google认为根据美国版权法“公平使用(Fair Use)”的信条是允许的。于是Google提供了从图书馆扫描出来的版权图书的片段预览。

图:图书片段预览
这场关于版权的诉讼一直到了今年才有了结,双方同意和解,正是这一和解协议引起了国内一些好事的人注意,从而掀起了“反对谷歌侵权”的风暴。中国似乎一夜之间就变得十分尊重版权。
和解协议
Google与作家、出版社达成了和解协议,协议仅在美国生效,根据和解协议,作家或出版社可以要求Google不扫描特定著作,或将已经扫描的书籍从Google图书搜索里移除。而如果作家和出版社不提出排除或除外请求,Google将享有以下权利:
1、继续数字化图书
2、向公共机构出售对电子书籍数据库的订阅
3、出售对个别书籍的网上查阅
4、出售在书籍的插页做广告
5、显示书籍预览或片段
6、显示书籍的简介、目录等周边信息
或许我们会有疑问,这不是霸王条约么?为什么作家和出版社愿意和Google达成这样的霸王条约?
因为根据和解协议,作家和出版社将会获得较大的利益:
1、作家和出版社可以决定版权图书以何种方式展示:全书预览、收费预览(价格也是可以自行决定的)。
2、Google图书搜索收入63%将支付给版权所有人,这些收入包括前面提到的广告、出售等。
3、在一定程度上增加销量。
4、获得至少60美元的赔偿。
其实60美元的赔偿不算什么,基本上可以忽略,作家和出版社愿意达成协议,很大程度上是看中了收入的分成,用过Google Adsense的人肯定知道,Adsense广告收入是很可观的。
如果你身在美国,你将能看到Google图书上的收费阅读功能,因为这个和解协议适用于美国境内。
中国作家的抗议
《新京报》2009年10月15日报道中国“文著协抗议谷歌侵权”,报道的主要内容如下:
中国文字著作权协会常务副总干事张洪波表示,有570位中国权利人的17922部图书未经授权就被谷歌使用。文著协将代表作者,维护中国版权合法权益。张洪波称,文著协也是今年才知道谷歌数字化图书馆中收录了未经授权的中国图书。
在报道中,《新京报》的记者强调Google只会对版权所有人支付至少60美元的赔偿,而只字不提63%的收入分成。其它媒体的报道也几乎没有提及收入分成这一点,甚至有媒体断章取义称Google仅支付60美元的赔偿。
CCTV2的《今日观察》也跟进了这一事件,报道视频如下:
看不到视频可以点击这里。
节目开始时,评论员刘戈做了一个荒唐的比喻,大家可以重点注意一下。
中国作家的抗议其实和当年美国作家的抗议如出一辙,不同的是,中国的媒体将问题扩大化,我甚至认为很多作家根本没有用过Google图书搜索就跟着其他人一起抗议,他们是真正的不明真相、被煽动群众。
默多克式的叫嚷
互联网提高图书销量
传媒大亨默多克经常谴责Google免费在网络上提供新闻搜索,认为那样损害了自己的利益,但新闻集团旗下的所有网站却没有一个在robots.txt里禁止Google,因为默多克即便已经白发满头,他依然能明白,没有了搜索引擎,他旗下的媒体更不好过。所以默多克叫叫也罢了,根本不需要理会。
叫嚷着被侵权的作家也是一样的。在互联网时代,试想如果一部图书在网上无法搜索到任何片段、没有任何介绍,谁会去买?现代人谁有大量的时间到图书馆或书店去翻阅图书?单靠口碑图书就能有很好的销量?
扫描不等于商业用途
Google图书搜索没有提供有著作权的图书的全书预览,反而提供其中的片段和简介,方便搜索者决定是否购买,如果这种做法也是侵权,那提供图书目录的当当网、提供书籍简介的豆瓣网是否也有侵权之嫌?
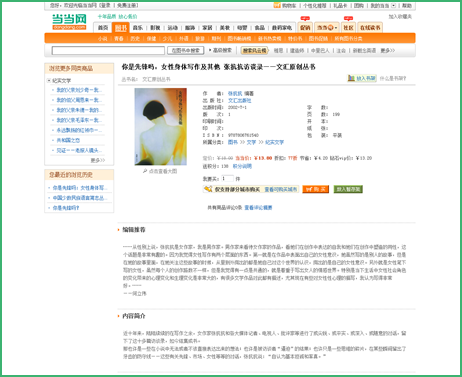
图:当当网上的张抗抗老师的图书《你是先锋吗》
是的,Google和当当网不同,Google还将图书扫描存档了。但是,就像个人购买图书一样,我们可以私下扫描图书、将图书存档到电脑里,这都是允许的,因为我们没有将这些资料用于商业行为。
同样的,Google也没有这样做,它做的事情和图书馆、和我们做的是一样的,它扫描了有著作权的图书,但并没有将这些内容在网上公开,也没有用于商业行为,在权利人没有允许的情况下,提供比当当网还少的图书简介和预览。
既然不能用于商业用途,那么Google扫描图书的用意何在?
长远来看,被扫描的图书肯定是要放到网上的,Google是在等待权利人的允许。
合作才是最好的出路
图书数字化是时代的趋势,纸质媒介终将被淘汰。与其进行诉讼,不如选择合作,作家、出版商与Google进行合作对于双方,乃至于全球网民都是有益的。因为:
1、Google可以极大其数据库,提供更好的搜索服务,获得更大的竞争优势。
2、作家、出版商可以通过Google图书搜索平台促进作品的销量,同时参与广告分成,获得额外的收入。
3、网民能免费获得更多的信息。同时,支付一定的费用后在网上就能获得资料,免除奔波图书馆的烦恼。
很多音乐网站都提供30秒试听服务,这个试听服务侵权了么?版权所有人为什么没有意见?因为这是一种双赢的策略。
图书预览也可以效仿音乐试听,盈利前景是可以预测的。
阴谋?
谷歌今年年初被CCTV整了一次,我现在还记忆犹新。谷歌因为在搜索框里提供关键词提示,而这些关键词提示不加人工干涉,被CCTV的专家们认为谷歌是故意为了吸引流量而做的“违背道德”行为。当时,在谷歌搜索框里输入“儿子”,就会出现“儿子和妈妈好爽啊”等关键词提示。

不知道是专家装傻还是真傻,这些关键词提示都是根据搜索频率决定的,中国网民爱搜索这些东西,责任却在Google身上去了。
CCTV2的《谷歌的无礼颠覆了什么》专题里,其中一位评论员对Google图书搜索表示担忧,他担心Google会故意挑选符合美国价值观的图书进行扫描。这个“担忧”到底暗示了什么,稍微动脑就能想到了。
同时,新华网、人民网(该网站可能含有恶意软件,有可能会危害您的电脑)相继出现抨击谷歌的舆论,醉翁之意在哪里,也是稍微动脑就能想到的。
(更新)人民网的无耻反击
2009年10月23日下午17:47分补充更新:
新华网刚刚发布一篇题为《谷歌标明"人民网读书频道可能含有恶意软件"? 》的新闻,内容主要认为Google不满人民网大面积报道Google图书搜索侵权行为,从而将人民网读书频道标记为“该网站可能含有恶意软件,有可能会危害您的电脑。”,摘录部分内容:
从谷歌已经无法直接点击进入人民网读书频道了。记者随后向人民网了解情况,据读书频道负责人介绍,这个情况他们也 发现了,已经有不少读者反映此事。但通过技术部门诊断,人民网读书频道页面完全正常,没有任何相关恶意软件。“况且读书频道与其他频道共用一台服务器,为 何只有读书频道被注明含有恶意软件?谷歌的检索结果里还有一个是繁体的人民网读书频道,点击去其实还是简体版本,就没有提醒含有恶意软件。”
但如何解释谷歌的检索结果?“原因很简单,我们从20日开始关注了谷歌数字图书馆涉嫌侵权中国作家的事情,并且做了相关专题。21日就被如此恶意封杀了”,读书频道的负责人解释到。
众所周知,Google搜索结果对恶意链接的判断,数据是来自第三方的StopBadware,Google将一个网站标示为可能含有恶意软件是因为发现了该网站里确实存在恶意代码,为了保护搜索者的安全,它就加上了那样一句标识。
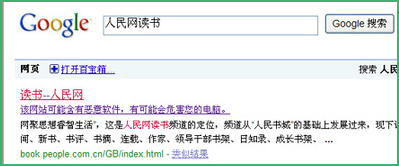
那么,人民网读书频道的负责人的回答是无耻还是无知,相信大家可以有一个非常清晰的判断。
附:Google对人民网读书频道页面的安全诊断报告:

这几天看到一大批所谓的主流媒体无耻的跟风批评谷歌,很无奈,还是这篇文章写得实在,有理有据,一针见血的揭露了事件的真相
大部分作家和记者既不了解谷歌的运营模式也不熟悉版权法,谁知道Google books和百度MP3搜索有什么本质区别——可想而知,就跟着上了。
至于法律条款,如果外行看不懂,那么跟电信、金融陷阱四伏的条款没什么区别。
卖IT、金融之类复杂的玩意,市场宣传一定要让外行明白在买什么帐,否则很容易出事。不是客户被商家骗(中国电信霸王条款、美国毒债券)就是商家被客户误解。
就是呢,不过貌似已经有作家开始反应过来了,Cnbeta上一篇文章《韩寒看谷歌图书馆计划:答案分两种》就说明了这一点:http://www.cnbeta.com/articles/96226.htm 其中一部分如下:最近经常有记者问我关于谷歌图书馆将包括我在内的几百名作家的图书扫描以后免费放在网络上阅读一事,做何感想。我当时对记者的回应是,这是不可以的,这不是一个大企业的态度。
后来我仔细查了一下新闻和报纸摘要,发现我自己也不知道我得到的资讯是否全面,所以,这个问题的答案是分成两种的。
第一种,假设谷歌的确扫描了全书,并在网络上提供免费阅读和下载,那么毫无疑问的,这是非法的。管你事后事前给钱这不重要,这尤其对传统图书作家有巨大的伤害。
第二种,假设谷歌扫描和摘录了图书的一个部分或者一些段落,并没有提供全文阅读,可显示和阅读的字数控制在一个很小的比例内,我个人并不认为这个行为违法。
我并不知道谷歌属于哪一种行为,如果是前者,严惩不贷,如果是后者,被人陷害。
可见韩寒已经反应过来了,不愿再被人家当枪使来不明就里的抨击谷歌了,虽然他故意说自己不知道是属于哪种情况有给自己打圆场的感觉,但毕竟能写出这些内容就比那些被作家协会支使着胡说八道的甚至连谷歌图书馆是怎么回事都不知道的知名作家真诚很多,也明智很多了!
哥们儿说的很对,我赞成。有本事去查bd的mp3搜索啊,如果来狠的,那就先自律一下嘛,正所谓己所不欲,勿施于人。看来zg自己的内功还是没练好啊!
凡事Google的就是正确的,凡事中国的就是错误的
我是google忠实用户,看完这文章我想说几句话:
1,我为自己是中国人而骄傲,为自己生在中国而耻。(回某楼的话,如果某天google真的像youtube那样被政府封了的话,我真的会自掐网线,卷铺盖移民x国,其实y网被封的时候哥就已经动此邪念了)
2,我坚信,google会进一步加深同诸如wikipedia这样的公益型网站的合作,其实w网的著作权解决方案是可以借给google用用的,中国没人骂w网吧?就因为它是公益的?
3,没有这些网站对世界性知识的维护和传播,地球将变得多么荒凉?变得仿佛中国的言论自由一样。说实话,我真的不希望看到镰刀斧头旗在全世界上空飘扬,不然的话,我就得把眼睛挖出来、耳朵割下来、舌头咬下来。不学习真理,也不诉说真相,就像今天一部分国人(如ccav )那样。
谷歌很多方面都走在前面,有钱没办法
Google的确对一些图书进行了全书内容扫描,这是无可非议的。因为在Google搜索一本书的任何一段文字(特有的,而非普遍存在的)都可以找到这本书的详细信息.比如我输入《Cries in the drizzle》中两个人物姓名,就可以找到书中关于他们之间的内容的预览。Google是没有侵权,但又点…
王小丫 你也真sb啦 操
理解一下建设喝血社会。
其实很大程度上来说,我们故意给Google找茬其实本意就是希望通过断章取义甚至胡编乱造的宣传,来让不明真相的人真的认为“Google是让人心神不宁的罪魁祸首”以及“它是国外别有用心者用来对付中国的工具”,以达到洗脑的作用。其实不用说远的,我是大学生,我身边没上过网的亲戚朋友,以及学校里那些每天只认识校内和魔兽的孩子们,他们当中就有人坚定的这样认为着。
我想对于真正乐于读书、懂得读书、读的懂书的明白人来说,Google图书对我们又是一个极大的帮助,想想豆瓣和当当这样的网站给我们带来多少方便就知道了。待到这个功能更加完善之后,我想它给我们读书者带来的便利应该又是质的飞跃。
现在google成了人人喊打的对象,我心痛啊!
每次关于Google的,这边总有文章。
人民群众,能在多大程度上通过言论和平地创造历史,我拭目以待。
这就是中国,不能拿中国的思维概论去思考这个问题,因为那样的话会永无止尽
对CCTV的脑残已经不需要说明了
水平低是一回事
别有用心的误导就是另外一回事了
百度是该笑还是该哭呢?
其实就是谷歌这些年没交够保护费,而且谷歌太自由了,什么东西都能让中国老百姓看到(这个谷歌图书馆能搜到很多禁书的),这样非常不“和谐”。
新华网,人民网,CCAV天天报道的事,你以为能是一个作协能领导的
谷歌应当去央视做广告。
前面都很支持,我就说下最后一点,文中“众所周知,Google搜索结果对恶意链接的判断,数据是来自第三方的StopBadware”是错误的。StopBadware是个第三方组织,但该组织并不主动去判断一个网站是否有所谓的恶意软件,而是由他们的合作方来报告数据,这点与本文作者对恶意连接的标志的理解完全相反。关于该事实,可以去看StopBadware的官方网站,StopBadware.org。Google是他们的合作方,所以google可以去提交它认为存在恶意软件的网站,当提交的数量超过一定数字的时候,就会被StopBadware标记为恶意网站,而不是被Google标记。当然如果被标记为恶意可以去StopBadware的网站提出诉讼,前几天经常去的一个游戏就被标为恶意网站,用firefox登陆就出现一个红页面(因为firefox的公司mozilla也是合作方)。然后我提出诉讼,StopBadware回复很快,当有诉讼的时候,StopBadware会再次检查数据合作方是否有新的报告,如果没有,他们会取消对该网站的恶意提示。一点点小小的评论。
最后补充一点,早在几年前(最少在05年的时候,美国google早就有图书馆这个东西了,很多图书都扫描在册),当时写论文查资料相当方便,比去图书馆来的容易多了,但跟中国谷歌的类似,很多图书都只有部分章节,或者部分页数。
说Google 图书能帮助些论文,我认为还是作用有限,毕竟没有全文。期刊数据库才比较合适。从宏观来看,Google毕竟是商业组织,盈利是其目的。当然建立品牌算是手段的,而且看起来挺成功的,不然怎么会那么多G粉~
个人觉得文章有倾向性不慎客观。如果都能用写论文的理性和逻辑来写博客文章可能会比较客观;不过博客可能承担不了那个功能。
至于CCTV,意识形态是显然的,但不能单纯的进行伦理判断。问题也有,可能比较缺乏新闻专业主义吧。
原来不只是不明真相的群众,还有大量不明真相的作家~~
我觉得这个淫秽书刊毒害特别大。就是我一个同学,他以前,就比较好奇这些东西,他就自己买淫秽书刊来看,搞得那段时间心神不宁。后来国家打击淫秽书刊,他就没再看,那段时间好了。
结果后来他又发现,通过新华字典这样比较权威的工具书可以找到这些淫秽的字词。然后就把这些字拼起来阅读,后来导致他又反复了。